

AI avatars are everywhere in 2025, powering everything from marketing explainers to internal training videos. But with so many tools claiming to be the best, how do you know which one actually delivers? I put five of the most popular AI Avatar platforms to the test using the same script, setup, and criteria to compare quality, speed, and usability. Here’s what I found: the good, the bad, and the jittery.
How I Tested These AI Avatar Tools
To give each platform a fair shot, I tested five of the top AI avatar tools using the exact same script—roughly one minute and thirty seconds when spoken aloud. I kept the test conditions simple and standardized: no background music, no B-roll, no added visuals. Just the avatar speaking directly to camera. I used the default stock avatars provided by each platform and timed how long it took from hitting “generate” to having a finished video in hand. That timing included everything the tool counted as “render time.”
Here’s the exact script, for reference.
AI avatars are digital personas—often lifelike 3‑D characters or stylized illustrations—whose movements, facial expressions, and voices are driven by artificial‑intelligence pipelines. At the core is a conversational language model that converts a user’s text or speech into a coherent, context‑aware response. That text then feeds into a neural text‑to‑speech (TTS) engine trained on large datasets of human voices, producing natural‑sounding audio while preserving nuances such as intonation and emotion.
To make the avatar “come alive” visually, several layers work in concert. Real‑time facial‑animation rigs map generated speech to mouth shapes (visemes) and blend them with pretrained gestures and micro‑expressions, often refined by reinforcement learning from human feedback to avoid uncanny movements. Some systems add a live video pose‑estimation layer or use depth cameras to mirror a user’s body language onto the avatar skeleton, while generative vision models handle hair, clothing, lighting, and background. Everything is composited in a rendering engine that synchronizes lip‑sync, head turns, and eye gaze to the TTS audio in just milliseconds.
Beyond the technical stack, production‑grade AI avatars layer on personalization and safety controls. Fine‑tuning lets creators train the language model on brand lore or an individual’s speech patterns, while voice‑cloning models capture specific timbres under user consent. Guardrails—such as toxicity filters, identity‑spoofing protections, and watermarking—help ensure ethical deployment. As GPUs and edge accelerators shrink latency, these avatars can now run inside video‑conferencing tools, games, or virtual‑production sets, making real‑time, emotionally attuned digital doubles increasingly accessible.
Visla
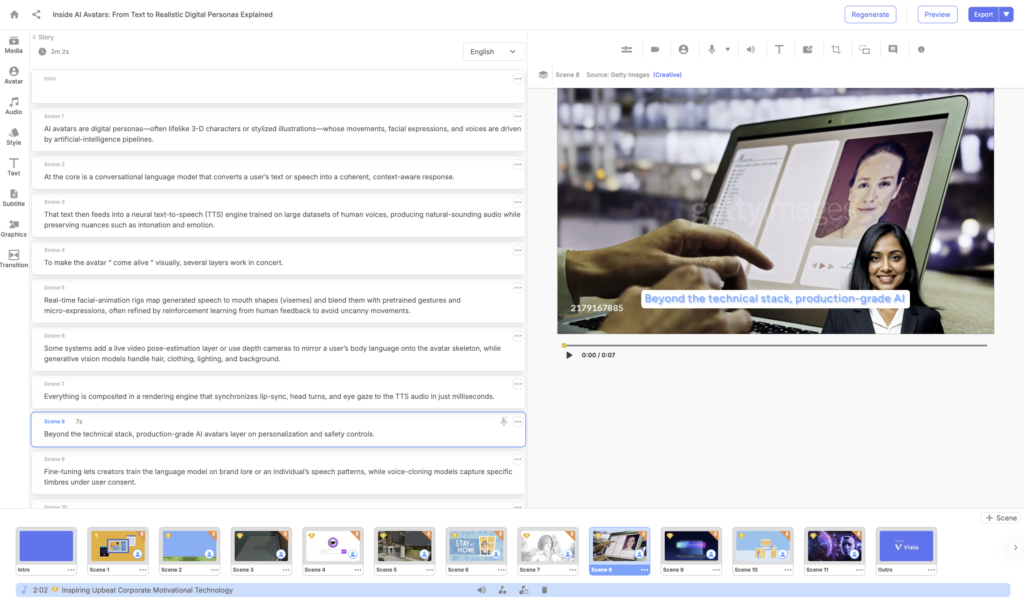
Visla offers both public and custom avatars, along with a user-friendly interface that gives creators full flexibility. You can create avatars using a prompt or photo, and customize everything from posture to clothing. The platform supports multilingual voiceovers, instant subtitle generation, and automated B-roll/music suggestions. Visla also includes scene-based editing, collaborative team features, and enterprise-level scalability.
My Experience with Visla
Yes, I work at Visla, but I approached this test with the same standardized conditions as the others. My video rendered in two parts (one for initial generation, one for final export) and totaled about 7 minutes and 14 seconds. Not only did it finish faster than most, but it also auto-selected appropriate B-roll and music. The avatar looked lifelike, and the lip-syncing was smooth and convincing. If you’re looking for fast, high-quality output with minimal fuss, Visla does the job and then some.
Synthesia
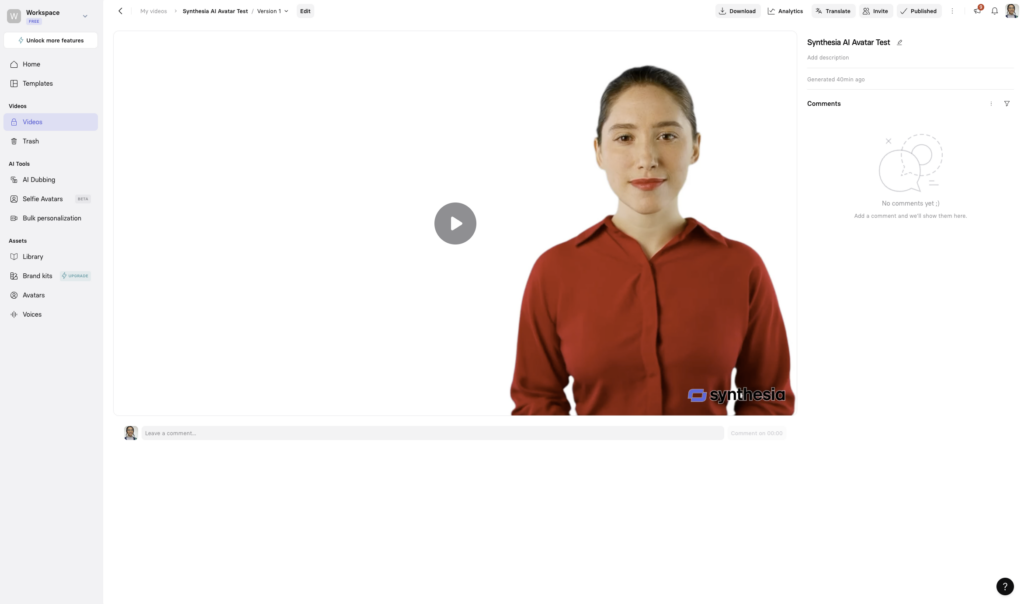
Synthesia is perhaps the most well-known AI avatar tool on the market. With a library of over 230 stock avatars and support for 140+ languages, it’s clearly designed for scalability. Beyond just stock avatars, you can also create personal avatars (with a webcam or phone), selfie avatars powered by Veo 2 tech, or high-end studio avatars crafted in professional environments. For enterprise customers, there’s an Avatar Builder feature that lets you brand existing avatars with your company’s colors and logos.
My experience with Synthesia
The interface is user-friendly and focused on productivity, although it nudges you into its pre-made templates quite a bit. That could be helpful for beginners but may feel limiting for more hands-on users. The total rendering time came to 6 minutes and 50 seconds, though I had to refresh the page after it got stuck at 100%. That could be an issue with my browser (I use Arc), but it’s worth noting. The final avatar looked excellent, with solid motion, expression, and lip sync. If you’re aiming for a corporate look and want reliability across languages, Synthesia remains a solid choice.
Descript
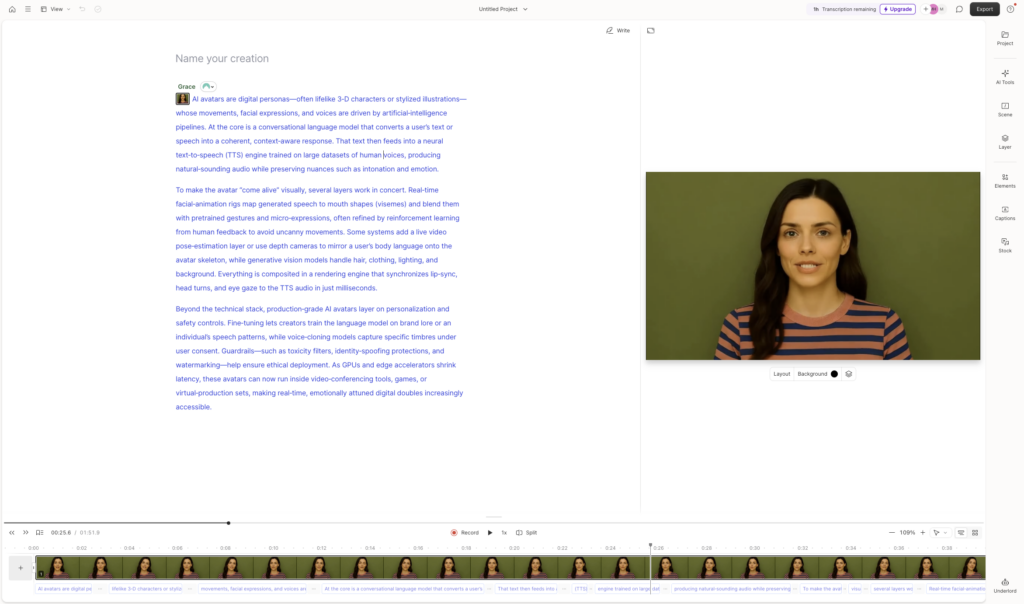
Descript offers a blend of stock and custom AI avatars that you can assign to speakers in your script. One of its unique features is that avatars are embedded directly into the transcript-based editor. This setup allows for dynamic script changes and transitions without ever leaving the editing environment. You can record your own voice, generate a matching AI avatar, and sync them together with lip-sync functionality. The avatars respond naturally even within transitions, making the videos feel more fluid. Descript is especially useful for internal training and business communication, where speed and integration matter more than ultra-high fidelity.
My experience with Descript
Descript’s interface is polished and mostly intuitive, especially if you’re used to editing by transcript. When it comes to AI avatar generation, the platform is right around average. It took 8 minutes and 24 seconds to render my basic video. While the avatars look decent and the lip-syncing is competent, the video still has that unmistakable AI-generated sheen: a bit of jitter, some motion blur, and a robotic cadence. It’s not a bad result, but it’s also not what I’d call production-grade. For a training deck or explainer, it gets the job done.
Colossyan
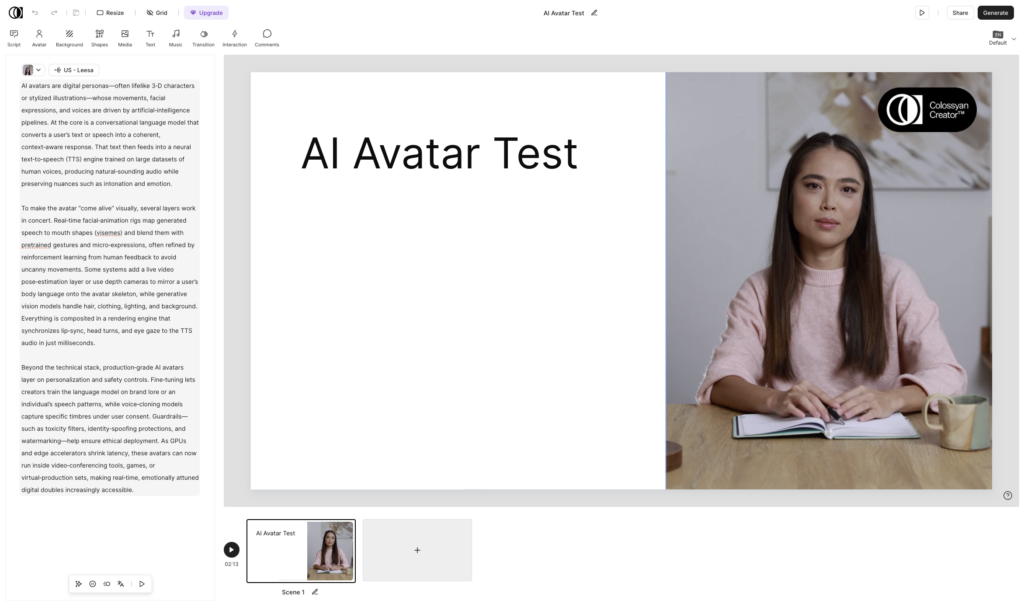
Colossyan provides a wide selection of over 200 diverse avatars, complete with lip sync, voice modulation, and multi-language translation. It also supports instant avatars from phone footage and voice cloning in 30+ languages. Its standout feature is the ability to create interactive content like multi-avatar conversations and embedded quizzes, a clear nod to e-learning and corporate training.
My experience with Colossyan
I started by testing their AI video creator, which automatically chops your script into scenes. This works well if you want automation but can be frustrating if you prefer full control. The template-heavy workflow isn’t necessarily bad, just something to keep in mind. I started over and made my video from scratch by simply plugging my entire script into a single scene. The video took 8 minutes and 17 seconds to render, and while the avatar looked great in a thumbnail, playback revealed sluggish gestures and a somewhat flat voice performance. The loading percentages jumped around randomly, which made it unclear how far along the process was. Good tool, but not my favorite for polish.
HeyGen

HeyGen takes a very expressive approach to avatars. Their Avatar IV and Avatar 3.0 models introduce realistic facial expressions, synced speech, hand gestures, and even full-body motion. You can generate avatars from a single photo, and their latest models can interpret tone, emotion, and even sing. This makes HeyGen particularly useful for creators aiming for personality-driven content or interactive video experiences.
My experience with HeyGen
I had to shorten my script to 840 characters due to the free plan’s limitations, which slightly skews the comparison. That said, the interface was smooth and modern. The main issue? Rendering speed. As of writing, it’s been over one hour and my video is still stuck at 18%. That’s a major issue for anyone working on deadlines. I’ll update the timing when it finally finishes, but based on current performance, HeyGen has potential but struggles with reliability at scale.
My final thoughts on AI Avatar tools
Each AI avatar tool has a distinct vibe and use case. Descript is ideal for integrated editing and internal comms, but slow to render. Synthesia is highly polished and multilingual, though it leans on templates. Colossyan caters to corporate learning, offering interaction but sacrificing some polish. HeyGen is ambitious and expressive, but currently unreliable. Visla offers the best overall balance: it’s fast, flexible, and delivers consistently high output.
FAQ
The best AI avatar tool in 2025 is Visla. It offers the strongest balance of speed, quality, and usability while giving creators a high level of control. Visla supports both custom and public avatars, delivers accurate lip sync with natural-sounding AI voices, and adds smart enhancements like B-roll and background music automatically. Unlike many other platforms, Visla renders quickly and reliably, making it a great fit for marketing, training, and internal communications.
Yes, many AI avatar platforms let you create your own avatar. Some, like Visla, allow you to upload a photo or prompt the AI to generate a digital replica of yourself. These avatars can often be customized with different outfits, postures, and voice options to match your brand style.
To make an AI avatar video, choose a platform like Visla. Enter your script, pick a stock or custom avatar, select a voice, and let the platform generate the video. Most tools include a preview step, allowing you to make changes to the script, timing, or avatar style before final export. Within minutes, you’ll have a complete video ready for download or sharing.
An AI avatar is a computer-generated human-like character that can deliver speech and expressions in a video. These avatars are powered by artificial intelligence to mimic natural speech patterns, lip movement, and facial gestures. They’re used in videos to represent a speaker without requiring actual human filming. AI avatars are widely used in marketing, education, onboarding, and product training.
AI avatars work by combining computer vision, voice synthesis, and motion modeling. You start with a script or prompt, and the AI engine generates synchronized audio and video using either a pre-made or custom avatar. The avatar “reads” your script using AI-generated or cloned voiceovers, lip-syncs the speech, and animates facial and body gestures to appear lifelike. The result is a video presenter that looks and sounds convincingly human, all without stepping in front of a camera.
May Horiuchi
May is a Content Specialist and AI Expert for Visla. She is an in-house expert on anything Visla and loves testing out different AI tools to figure out which ones are actually helpful and useful for content creators, businesses, and organizations.